
Introduction
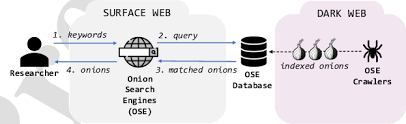
Talking about how onion search engines Index, one must bear in mind that the hidden web operates differently from the public internet. Traditional search engines rely on crawlers that follow hyperlinks, collect page data, and organize results into massive databases. However, onion services exist inside a decentralized environment where websites frequently change addresses, disappear, or restrict access. As a result, indexing hidden services presents unique technical challenges.
Understanding how an onion search engines index functions helps researchers, privacy advocates, and cybersecurity professionals better understand darknet discovery methods. Unlike Google or Bing, onion-focused search tools often work with smaller datasets and face constant volatility across the Tor ecosystem.
For more insight, please explore dark web search engines overview and how hidden services are discovered
Many users assume darknet search engines operate exactly like surface web alternatives. In reality, they use specialized crawling techniques, verification methods, and ranking systems to maintain searchable collections of onion sites. Understanding these mechanisms provides valuable insight into how hidden services become discoverable across the Tor network.
Why Indexing Onion Sites Is More Difficult
Building and maintaining an onion search engines index requires overcoming obstacles rarely encountered on the public web. Onion services often change addresses, disappear without warning, or limit crawler access. Consequently, search engines must continually verify whether indexed resources remain available.
Many hidden services intentionally avoid visibility. Operators frequently restrict automated traffic to reduce unwanted attention or malicious activity. Therefore, search engines cannot rely solely on automated crawling to discover content.
Additionally, the decentralized structure of the Tor network creates challenges for data collection. Unlike conventional websites connected through extensive hyperlink networks, many onion services have few inbound references. This lack of connectivity makes discovery more difficult.
To learn more, please explore Ahmia dark web search and understanding darknet infrastructure
Furthermore, search providers must distinguish between active, inactive, duplicated, and fraudulent resources. Without continuous monitoring, search results quickly become outdated. This constant turnover explains why darknet indexes often contain fewer results than mainstream search engines while requiring significantly more maintenance.
How Onion Crawlers Discover New Hidden Services
The foundation of any onion search engines index is discovery. Search engines must first identify onion services before indexing their content. Several methods contribute to this process.
Some crawlers begin with known directories and publicly available onion link collections. From there, they follow references found within indexed pages. Although this resembles traditional search engine crawling, the process occurs on a much smaller scale.
Researchers and community members also contribute discoveries. Many onion directories accept submissions from users who identify new hidden services. These submissions provide valuable expansion opportunities for search providers.
To get more information, please review Haystak dark web search.
In addition, some search platforms monitor discussion forums, research communities, and publicly shared onion references. This approach helps identify emerging resources before they become widely known.
Once discovered, search engines typically verify accessibility before adding pages to searchable databases. Verification helps reduce dead links and improves result quality. As a result, reputable search platforms emphasize validation rather than simply collecting large numbers of URLs.
How Search Engines Build an Onion Search Engines Index
After discovery, the next step involves creating an organized onion search engines index. Search systems collect metadata, page titles, descriptions, keywords, and content signals that help categorize websites.
Crawlers analyze page structure similarly to conventional search engines. They identify relevant text, headings, navigation elements, and contextual information. These elements help determine topic relevance and improve search accuracy.
However, indexing hidden services often requires additional filtering. Search engines frequently encounter duplicate pages, temporary mirrors, and inactive resources. Therefore, quality control plays a larger role in darknet indexing than in traditional web search.
To explore further, please check dark web search engines.
Search providers also classify content into topical categories such as privacy tools, cybersecurity resources, research platforms, communication services, and technology communities. Categorization improves discoverability while helping users navigate large collections of onion sites.
As the index grows, ranking systems evaluate factors such as availability, relevance, freshness, and user engagement signals. These metrics help determine which pages appear first in search results.
Verification and Quality Control in Onion Search Results
Maintaining accuracy remains one of the most important aspects of indexing hidden services. Because darknet resources frequently change, search providers must continually validate their databases.
An effective onion search engines index includes recurring checks for uptime and accessibility. Search engines routinely revisit known addresses to confirm they remain operational. If a service becomes unavailable, rankings may decrease or listings may be removed entirely.
Verification also helps identify cloned sites and fraudulent copies. Many malicious operators imitate popular services to deceive visitors. Consequently, search engines often evaluate consistency across multiple observations before trusting a listing.
To understand better, please review DuckDuckGo Tor search.
Some search providers additionally use community reporting systems. Users can flag inactive pages, suspicious resources, or incorrect listings. This collaborative approach improves overall data quality and helps reduce misinformation.
Because the hidden web evolves rapidly, continuous verification remains essential for maintaining trustworthy search results.
Ranking Factors Used by Onion Search Engines
While exact algorithms differ among platforms, most onion search engines evaluate similar factors when organizing results. Relevance remains a primary consideration. Pages that closely match user intent generally appear higher in search rankings.
Another important factor involves availability. Search providers favor resources that demonstrate consistent uptime. Sites that frequently disappear may gradually lose visibility within the index.
Freshness also matters. An updated onion search engines index often prioritizes recently verified resources over outdated listings. This approach helps improve reliability and user trust.
For more insight, please explore Tor Project.
Content quality influences rankings as well. Pages with meaningful descriptions, clear structure, and useful information often perform better than thin or duplicated content.
Finally, some platforms consider external references. When multiple trusted sources link to the same onion service, search engines may view it as more authoritative. Although ranking systems vary widely, the goal remains consistent: helping users discover relevant and accessible resources.
FAQ
What is an onion search engine index?
An onion search engine index is a searchable database of discovered onion services. It contains information collected through crawling, submissions, verification processes, and content analysis. Search engines use the index to provide relevant results when users search for hidden services.
How do onion search engines find new websites?
Most platforms discover new onion services through crawler activity, directory references, user submissions, and community-shared links. They often begin with known resources and expand by following discovered connections. Continuous monitoring helps identify emerging services across the network.
Why do onion search results contain dead links?
Hidden services frequently change addresses or go offline permanently. Because the darknet experiences constant turnover, some indexed pages may become unavailable before the next verification cycle. Reputable search engines regularly remove inactive listings to improve result quality.
Are onion search engines as comprehensive as Google?
No. The hidden web contains fewer publicly accessible resources and significantly less interconnected content. Additionally, many onion services intentionally avoid discovery. As a result, darknet indexes are typically smaller and less comprehensive than mainstream search engines.
How do search engines verify onion services?
Verification usually involves checking accessibility, confirming uptime, reviewing page consistency, and monitoring changes over time. Some platforms also incorporate community feedback to identify inaccurate listings. This combination helps maintain trustworthy search results despite frequent network changes.
Conclusion
Understanding how an onion search engines index operates provides valuable insight into the discovery and organization of hidden services. Unlike traditional search engines, onion-focused platforms must navigate constantly changing environments, limited visibility, and frequent service disruptions.
Despite these challenges, modern darknet search tools continue improving their crawling, verification, and ranking processes. Through continuous discovery efforts, quality control measures, and ongoing validation, they help users locate relevant resources across the Tor ecosystem. As the hidden web evolves, indexing technology will remain a critical component of darknet research and information discovery.