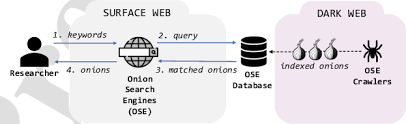
Understanding how onion search engines index hidden services is essential for anyone researching the dark web. Unlike surface-web search engines, these systems operate in an environment where instability, anonymity, and intentional obfuscation are core features rather than technical flaws.
Because onion services frequently appear, disappear, or relocate, indexing on the dark web follows entirely different rules. This article explains how onion search engines collect data, what limitations exist, and why no index can ever be complete. Explore more on onion link validation process, how new dark web marketplaces appear and search trends in the dark web
What Onion Search Engines Are Designed to Do
Before examining how onion search engines index content, it helps to clarify their purpose.
These platforms are not built to catalog the entire dark web. Instead, they aim to provide partial visibility into a constantly shifting network of Tor-based services. As a result, indexing is selective, temporary, and often incomplete by design.
Most onion search engines focus on:
- Discovering publicly reachable onion services
- Cataloging metadata rather than full content
- Maintaining short-term snapshots
- Supporting research and discovery, not browsing convenience
This limited scope explains why results differ dramatically between engines.
How Onion Search Engines Index Dark Web Sites
The way onion search engines index sites differs fundamentally from surface-web crawling.
Instead of continuous automated crawling, indexing usually relies on a mix of controlled discovery methods. These methods reflect the fragile nature of onion services and the technical limits of Tor routing.
Common indexing methods include:
- Manual onion URL submissions
- Limited crawler sessions with strict timeouts
- Static snapshot indexing
- Community-maintained discovery lists
Because of these constraints, indexes decay quickly and must be refreshed constantly.
Manual Submissions and Controlled Crawling
Many onion services are discovered through manual submission, not automated crawling.
Operators submit URLs directly to search engines, often along with basic descriptions. Crawlers then attempt short, controlled visits to confirm availability. However, deep crawling is rare because it can overload services or expose operators.
This approach explains why indexes remain shallow and fragmented across platforms.
Snapshot Indexing and Index Decay
Rather than live indexing, most onion search engines rely on snapshot-based indexing.
A crawler captures a page at a specific moment and stores limited metadata. If the service later goes offline, the indexed record may remain visible long after the site disappears.
As a result:
- Search results often include dead links
- Content freshness is inconsistent
- Verification becomes essential
This behavior is a structural limitation, not a flaw.
Differences Between Major Onion Search Engines
Not all platforms index the dark web in the same way. Each engine applies its own filtering rules, crawl depth, and moderation policies.
Understanding these differences helps researchers interpret results accurately.
Ahmia: Selective and Research-Focused Indexing
Ahmia emphasizes transparency and research usability. It applies filtering to reduce exposure to harmful content and documents its indexing approach.
A deeper explanation is available in Ahmia Dark Web Search Guide and Ahmia onion indexing system
Ahmia typically indexes fewer services, but results are more stable and suitable for academic or OSINT research.
Torch: Broad Indexing with Minimal Filtering
Torch maintains one of the largest known onion indexes, but with limited moderation.
Its crawler accepts more submissions and applies fewer restrictions. Because of this, results are broader but often less reliable.
For a detailed breakdown, see Torch Dark Web Search Engine Explained and AI content visibility on the dark web
Researchers often use Torch for volume analysis rather than trust-based discovery.
Haystak: Keyword-Driven Indexing
Haystak focuses on structured keyword indexing and historical persistence.
Instead of breadth, it emphasizes discoverability through long-tail queries. This makes it useful for tracking recurring terms or themes over time.
Further explanation is covered in Haystak Dark Web Search Engine Explained and dark web privacy tools explained
DuckDuckGo (Tor Version): Indirect Discovery
DuckDuckGo does not directly crawl most onion services. Instead, it acts as a Tor-compatible gateway for surface-web content and curated onion references.
This distinction is explained in DuckDuckGo Tor Search Explained
As a result, DuckDuckGo supports privacy-first research rather than dark-web indexing itself.
Why Onion Indexes Are Always Incomplete
Even the most advanced platforms cannot fully index the dark web.
Several structural factors prevent comprehensive indexing:
- Onion services intentionally block crawlers
- Frequent URL rotation and downtime
- Authentication walls and invite-only access
- Legal and ethical constraints
Because of this, onion search engines index only what is voluntarily exposed or temporarily reachable. For more knowledge, checkout our article on finding dark web forums and AI impact on dark web indexing
Risks of Misinterpreting Search Results
Without understanding indexing mechanics, researchers may draw incorrect conclusions.
Common mistakes include:
- Assuming dead links indicate takedowns
- Treating indexed results as authoritative
- Ignoring snapshot age
- Confusing mirrors with originals
Effective research requires cross-engine comparison and contextual analysis.
Verified External Authorities:Onion Search Engines Index
From an infrastructure perspective, the Tor Project explanation of onion services provides essential background on how hidden services function
For privacy-focused search behavior, the EFF guide to private search tools offers additional context
From a threat-analysis viewpoint, Europol outlines challenges related to dark-web visibility in its overview of dark web threats
FAQs: Onion Search Engine Indexing
Do onion search engines crawl continuously?
No. Most rely on short crawl sessions and snapshot indexing.
Why do results differ between engines?
Each platform uses different discovery sources, filters, and crawl limits.
Can any engine index the entire dark web?
No. Structural and intentional barriers make full indexing impossible.
Conclusion: Onion Search Engines Index
Understanding how onion search engines index dark web sites is critical for accurate research. These platforms do not offer completeness. Instead, they provide limited visibility shaped by technical, ethical, and operational constraints.
When used correctly, onion search engines support discovery and analysis. However, results must always be interpreted with caution, context, and verification. Ultimately, knowing how indexing works matters more than the results themselves.